golang面试题
面试一
make和new的区别?了解过golang的内存管理吗?调用函数传入结构体时,应该传值还是指针?
线程有几种模型?goroutine的原理了解过吗,讲一下实现和优势?
Goroutine什么时候会发生阻塞?
GMP模型中Goroutine有哪几种状态?线程呢?
每隔线程/协程占用多少内存知道吗?
如果Goroutine一直占用资源怎么办,GPM模型怎么解决这个问题?
如果若干个线程中一个线程OOM,会发生什么?如果是Goroutine呢?项目中遇到过OOM吗,怎么解决的?
项目中错误处理怎么处理?
如果若干个Goroutine,其中一个panic,会发生什么?
defer可以捕获到其Goroutine的子Goroutine的panic吗?
自定义一个error吗?
gRPC,自己封装了一下,利用gRPC gateway提供了http的方式
gRPC gateway怎么做的?社区的gRPC gateway库,通过proto文件添加描述信息,生成http的访问方式
proto文件怎么管理的?monorepo
服务发现怎么做的,也是通过gateway吗?
注册中心挂了怎么办?
开发使用过Gin框架吗?Gin怎么做参数校验?中间件使用过吗?怎么使用的
Gin的错误处理使用过吗?Gin中自定义校验规则知道怎么做吗?自定义校验器的返回值呢?
反射用过吗?原理了解吗?实际使用过吗? 我们自己的gRPC的业务框架就统一定义了参数的校验,通过反射在tag里面去埋一些具体的规则,在参数验证方法里面传进来的参数验证,通过反射里面的tag获取它的定义,去判断是否符合条件。
实现使用 字符串函数名 调用函数
1 | package main |
golang的锁机制了解过吗?Mutex的锁有几种模式(正常模式和饥饿模式),分别介绍一下?Mutex锁底层如何实现? channel用过吗?有什么值得注意的地方?(官方推荐不要用共享内存来操作变量,使用channel来传递)
数据库用过哪些?MySQL的锁机制了解吗?redis的分布式锁(redlock) redis数据类型,应用场景?redis的持久化你们怎么做的?你们使用MySQL用orm操作了吗(gorm、xorm)?MySQL分库了吗?
实现一个负载均衡算法
1 | // 随机算法 |
面试二
自我介绍,顺便说到了go micro微服务框架
说一下下面代码中哪个效率更高?为什么?
1 | const matrixLength = 20000 |
CPU的局部性原理
两个函数的差别就在 数值交换的那一行代码。第一个函数的效率会更高一点,涉及到CPU的cache内容,现在cpu通常会有三级缓存,cache的加载是一个内存对齐的加载,它是每次以固定的长度加载的一个数据到cache中。第一个函数可以使用到cache提速的效果,因为它读取的内存的变量的话都是在连续的内存里面的;像第二个函数,这个二维数组的话,每循环一次的话,它读取的变量都是不连续的,就会涉及到重新加载,从内存里面读取数据到cache,还会涉及到当cache不充足的情况下可能会涉及到cache的时效,还有就是修改这些内容就会导致整个运行的速度会更慢,没有充分利用到cache加速的效果。
如果是多核cpu,cache是怎么保持不冲突和一致的吗?(缓存一致性协议:修改、独占、分享、失效四种状态)
如果是多核的情况下,有个解决方案就是MESI,就是把一个内存cache里面的状态设置成4个状态,其实是两个bit来表示四种状态:修改、独占、共享、失效四种状态。它们设计到状态更新的话,比如说我把内存里面的一块数据加载到cache里面的话,如果某一个内核它对这个数据加载到当前这个内核的cache里面的话,然后这个内核对数据做了修改,这种情况下它就是一个修改状态,但是因为只有这一个CPU内核加载了这个资源,它属于修改但是独占的状态。如果另外一个内核再去读取相同的数据资源的时候,它就会检测到另外一个内核去加载这个数据,这个时候他的状态就会从一个独占状态变成一个共享的状态,之前读取内核的数据的状态就会变成一个失效的状态,新的内核就重新从内存里面加载数据到cache里面。 当一个数据处于一个共享的状态,比如两个内核都加载同一份数据到它内核的cache里面的情况。还有就是 当一个内核去修改了一份数据,另外一个已经加载了同样的数据到cache里面的这个数据。
uint类型溢出
你觉得这段程序运行结果是什么?
1 | func main() { |
uint类型的最大值。如果操作系统是32位,就是2的32次方减1;64位操作系统就是2的64次方减1
go是一个强类型语言,uint类型计算结果最后也是一个uint类型,uint1-2可以转换成0-1,也就是0+(-1),负数的计算都会转成补码,-1的补码其实就是所有位数都是1,最终结果就是所有位数都是1的二进制数,然后以一个无符号的数据识别的话,就是一个当前位数的最大值
介绍rune类型
rune类型和int32类型差不多,但还是有差别的,主要差别就是它用来做一个字符长度的计算的,特别是当中文做字符长度计算就会用到rune数组,用int32数组计算出来的是字节的长度
编程题:3个函数分别打印cat、dog、fish,要求每个函数都要起一个goroutine,按照cat、dog、fish顺序打印在屏幕上100次。
1 | package main |
介绍一下channel,无缓冲和有缓冲区别
是否了解channel底层实现,比如实现channel的数据结构是什么?
channel是否线程安全?
Mutex是悲观锁还是乐观锁?悲观锁、乐观锁是什么?
Mutex几种模式?
Mutex可以做自旋锁吗?
介绍一下RWMutex
项目中用过的锁?
介绍一下线程安全的共享内存方式
介绍一下goroutine
goroutine自旋占用cpu如何解决(go调用、gmp)
介绍linux系统信号
goroutine抢占时机(gc 栈扫描)
Gc触发时机
是否了解其他gc机制
Go内存管理方式
Channel分配在栈上还是堆上?哪些对象分配在堆上,哪些对象分配在栈上?
介绍一下大对象小对象,为什么小对象多了会造成gc压力?
项目中遇到的oom情况?
项目中使用go遇到的坑?
工作遇到的难题、有挑战的事情,如何解决?
如何指定CPU指令执行顺序?
面试三
内存逃逸
什么是内存逃逸
程序会被编译器分为栈区、堆区、全局变量区、数据区、代码区共五个区
- 栈区:主要存储函数的入参、局部变量、出参当中的资源由编译器控制申请和释放。
- 堆区:内存由程序员自己控制申请和释放,往往存放一些占用大块内存空间的变量,或是存在于函数局部但需供全局使用的变量。
Go的内存分配由编译器决定对象真正的存储位置是在栈上还是在堆上,并管理他的生命周期。
内存逃逸是指原本应该被存储在栈上的变量,因为一些原因被存储到了堆上。
问题:如果使用关键字new申请的对象还会被存储到栈上吗?
即使是用new申请的内存,如果编译器发现new出来的内存在函数结束后就没有使用了且申请内存空间不是很大,那么new申请的内存空间还是会被分配在栈上,毕竟栈访问速度更快且易于管理。
如:
1 | package main |
使用逃逸分析命令go build -gcflags="-m" main.go
可以看到new申请的内存空间被分配到栈上而不是在堆上
内存逃逸的场景
第一种情况变量在函数外部没有引用,优先放到栈中
最典型的例子就是刚刚说的new的内存分配问题,当new的内存空间没有被外部引用,且申请的内存不是很大时就会被放在栈上而不是堆上。
第二种情况变量在函数外部存在引用,必定放在堆中
1 | package main |
可以看到局部变量num从栈逃逸到了堆上。原因也很简单,因为在main函数中对返回的指针point做了解引用操作,而point指向的变量num如果存储在栈上会在函数showpoint结束时被释放,那么在main函数中也就无法对指针point做解引用的操作了,所以变量num必须要被放在堆上。
第三种情况超过64k的内存占用放到堆上
1 | package main |
当make申请的内存空间大于8192*sizeof(int)/1024=64个字节时,会到堆上申请内存。因为在Go1.3之后用连续栈取代了分段栈,Go1.4中连续栈的初始大小为2kb,频繁的栈扩缩容会导致性能下降,所以在达到阀值64kb时会在堆上申请内存而不是在栈上。这里还有例子就是在make申请的切片大小为一个变量时也会在堆上申请内存而不是栈上。
第四种情况make创建的切片值为指针
1 | package main |
这里似乎和前面说的第一种情况变量在函数外部没有引用,优先放到栈中有所违背。其实不然,假设这里创建的切片存储了大量的指针,那么对于当中的每一个指针都需要做变量在外部是否被引用的验证,这样大量的切片取指针,验证操作都会带来性能的损耗,所以当切片中存储的是指针时,索性将切片中指针指向的栈上的变量全部放到堆上。
深入理解make和new
new的使用
问题:new你应该常用吧,来看看下面这段代码运行结果是什么?
1 | package main |
这在运行时会发生panic
首先看一下关键字new的函数声明:
1 | func new(Type) *Type |
Type是指变量的类型,可以看到new会根据变量类型返回一个指向该类型的指针。
执行指令go build -gcflags="-l -S -N " main.go
1 | "".getStudent STEXT size=86 args=0x8 locals=0x20 |
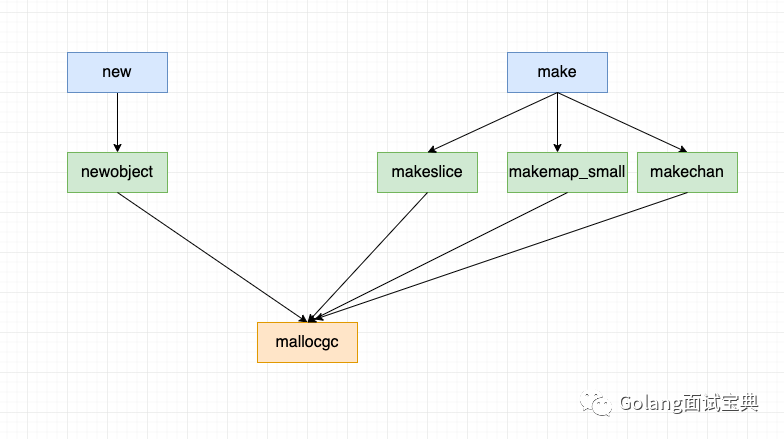
可以看到new底层调用的是runtime.newobject申请内存空间
1 | func newobject(typ *_type) unsafe.Pointer { |
newobject的底层调用mallocgc在堆上按照typ.size的大小申请内存,因此new只会为结构体Student申请一片内存空间,不会为结构体中的指针age申请内存空间,所以第10行的解引用操作就因为访问无效的内存空间而出现panic。
对于结构体指针,工作中一般使用s:=&Stuent{age: new(int)}的方式赋值,这样能够清晰的知道结构体中的每一个字段是什么,避免不必要的错误!
make底层
问题:那你再看看下面这段代码
1 | package main |
程序在运行时也会出现panic,先看一下slice的底层实现
1 | type slice struct { |
这就和上面的例子一样了,new只会为结构体slice申请内存,而不会为当中的array字段申请内存,因此用(*nums)[0]取指会发生panic。
如果需要对slice、map、channel进行内存申请,则必须使用make申请内存,下面看一下make函数声明:
1 | func make(t Type, size ...IntegerType) Type |
可以看到make返回的是复合类型本身,将错误代码修改如下:
1 | package main |
执行指令go build -gcflags="-l -S -N " main.go(这里只截取make相关)
1 | ... |
可以看到make在申请slice内存时,底层调用的是runtime.makeslice
1 | func makeslice(et *_type, len, cap int) unsafe.Pointer { |
可以看到makeslice申请内存底层调用的也是mallocgc,从这点看和new一样,但是细看new中mallocgc第一个参数(申请内存大小)用的是type.size,而make中的mallocgc第一个参数是mem,从MulUintptr源码中可以看出mem是slice的容量cap乘以type.size,因此使用makeslice可以成功的为切片申请内存。
1 | func MulUintptr(a, b uintptr) (uintptr, bool) { |
make为map和channel申请内存底层分别是runtime.makemap_small,runtime.makechan,也是同样调用mallocgc,这里就不继续讨论了。
make和new的区别
相同点:
- 都是Go语言中用于内存申请的关键字
- 底层都是通过mallocgc申请内存
不同点:
make返回点是复合结构体本身,而new返回的是指向变量内存的指针make只能为channel,slice,map申请内存空间