01-文件处理
字符编码
字符编码就是二进制和字符的映射关系
文本编辑器存取文件的过程
- 打开编辑器就是启用动了一个进程,进程就是在内存里的,所以写的内容就在内存里,断电了数据就会消失
- 保存之后,编辑器就会把内存的数据记录在硬盘上
- 我们平时写的py文件,与编写其他文件没什么不同,就是写了一堆字符
python解释器执行py文件的原理
- python解释器启动,此时就相当于启动了一个文本编辑器
- python解释器就相当于一个文本编辑器,打开了一个py文件,也就是从硬盘上把文件内容读入到内存中
- python解释器执行刚刚加载到内存中的代码
python解释器与文本编辑器的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备py文件的功能,这一点与文本编辑器一样。
不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不会在意python的语法,而python解释器将文件内容读入内存之后,会识别Python语法。
什么是字符编码
计算机只认识0和1,而我们现在输入的字符计算机是不认识的,必须要经过一个转换过程使得计算机识别人类的字符:
字符……翻译过程……数字
反正就是有这样的一种对应关系,能实现人类字符与数字的对应关系,这玩意称为字符编码表
字符编码发展史和分类
早期的计算机是美国人搞出来的,搞了一个ASCII表,但这只是美国的标准,而其他国家不能用。因为此刻的各种标准都只是规定了自己国家的文字在内的字符跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱码。
接着万国编码Unicode应运而生,但是在纯英文字符中发现,Unicode比ASCII多一倍的空间,这样UTF-8就出现了。
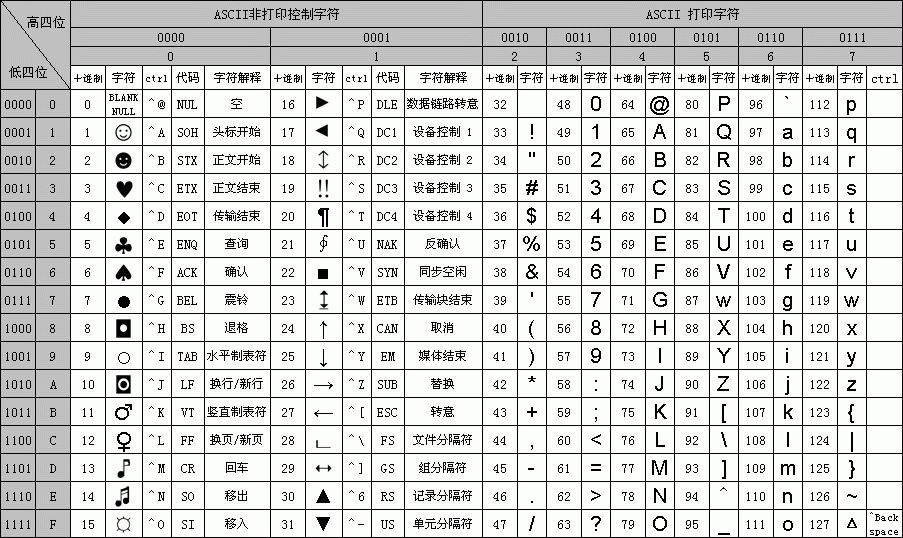
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
总结
以上这些基本是废话,记住以下两句话就够了:
- 内存中unicode取,用utf8存入硬盘,现在全世界的人写代码/写文件都是utf8
- 用什么编码写,就用什么编码读
python2与python3字符编码的区别
执行python程序的三个阶段
准备一个test.py文件测试,文件内容是以utf8的格式保存的
阶段一:
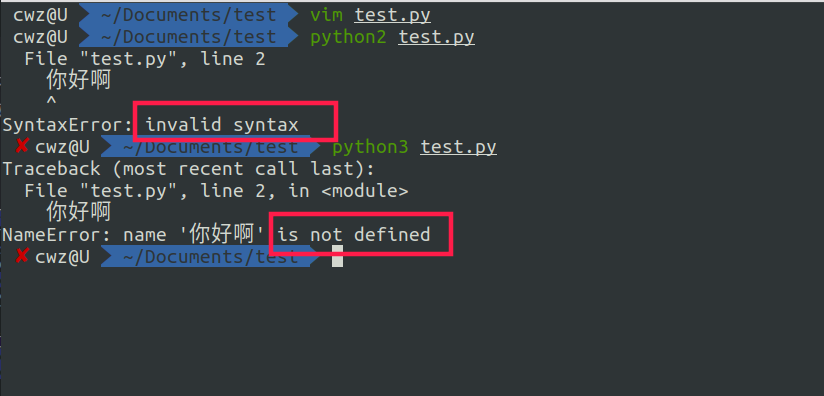
启动python解释器,python解释器相当于一个文本编辑器,把test.py中文件内容从硬盘读取到内存中。如果test.py文件中 不指定读取的编码格式,那么python就会使用默认的编码格式读取内容。
查看python2与python3默认使用的字符编码
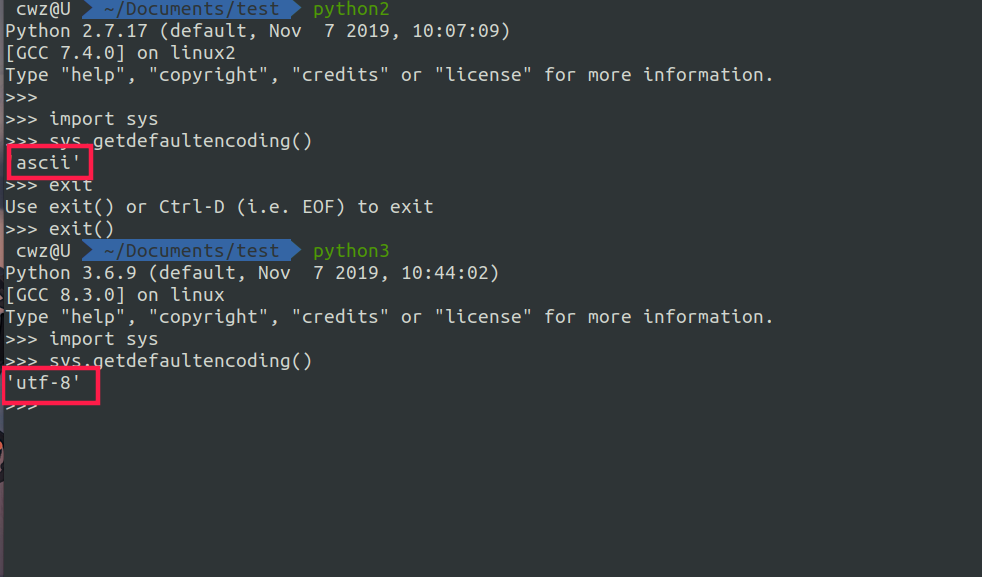
使用sys.getdefaultencoding()获取各自的编码格式,发现python2默认用ascii码读取字符,而python3默认用utf-8读取字符。
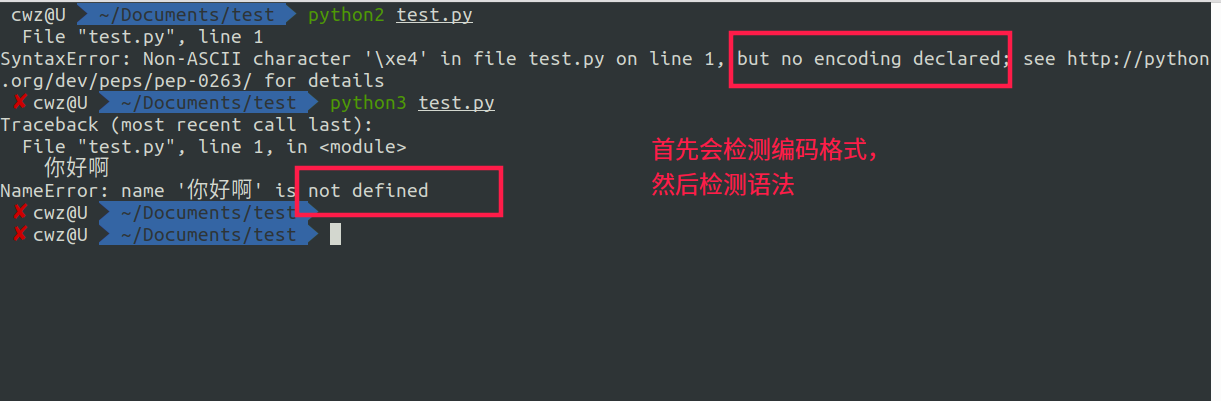
不指定编码格式,直接分别用python2和python3读取其中的内容:
指定编码格式为utf8,读取:
1 | #coding:utf8 |
总结:
- 对于Python2来讲,python解释器在读取到中文字符的字节码时,会先查看当前代码文件头部是否指明字符编码是什么。如果没有指定,则使用默认字符编码
ASCII进行解码,导致中文字符解码失败。 - 对于python3来说,过程是一样的,只不过python3的解释器以
utf-8作为默认编码,但这并不能兼容中文字节的问题。在windows中,可能文件保存为gbk的形式存入硬盘中。python3解释器执行该代码时,会试图用utf-8来解码,那肯定会出错。
阶段二
读取已经加载到内存的代码,然后执行,执行过程中可能会开辟新的内存空间,比如说msg = 'hello',
在程序执行前,内存中确实是以Unicode的格式放于内存中的。但是在程序执行过程中,会申请内存空间存放python的数据类型的值。
比如说msg = 'hello',会被python解释器识别为字符串,会申请内存空间来存放字符串类型的值,至于该字符串类型的值被识别成何种编码存放,这就与Python解释器的有关了,而Python2与Python3的字符串类型又有所不同。
阶段三
将读取的内容打印到终端,若终端的编码格式是utf-8:
- 在Python2中如果指定了字符编码,那么内存存取就会按照指定的字符编码去入内存。解释或去执行时就要按照指定了的字符编码去解释,否则就会乱码。 否则可以在定义变量前面加上u,如
u('中'),这样变量就会以unicode编码存入内存。 - 但在Python3中就不会有这样的问题,因为无论你指定了什么字符编码,都会使用Unicode编码去存入内存,Unicode编码可以和任意的字符编码相互转换,并在读取时按照所需的编码去读取,这样就很好解决了字符编码的问题
python2与python3 字符串类型的区别
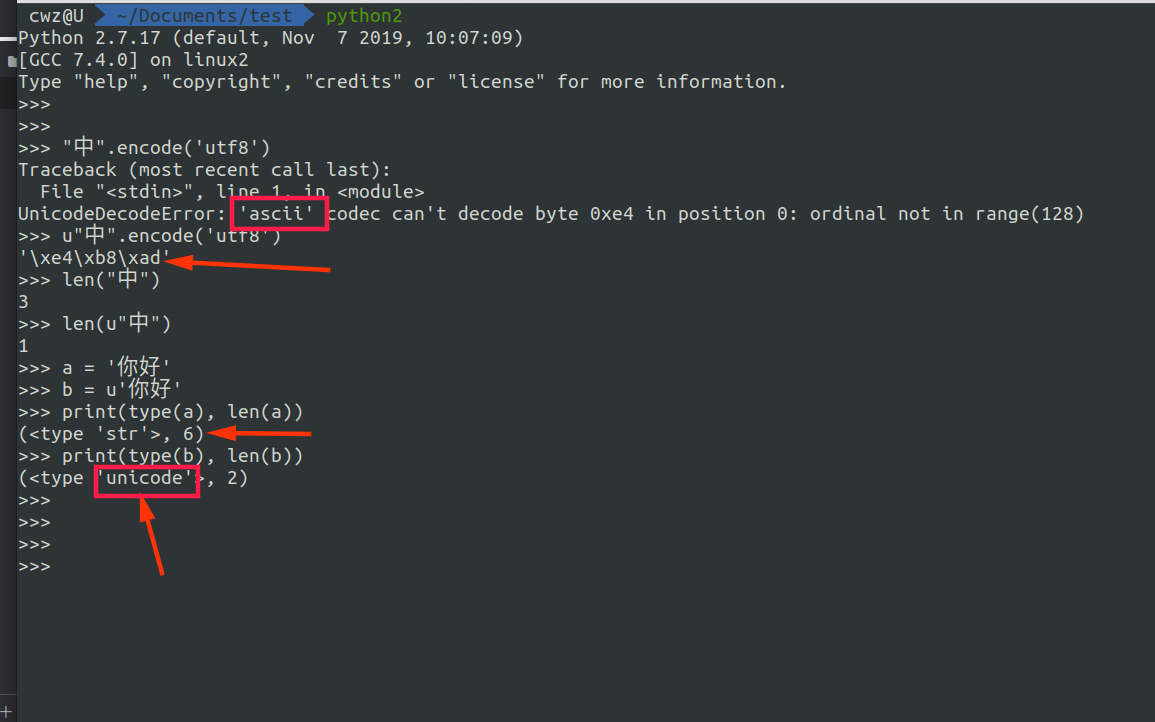
python2字符串类型
1 | class basestring(object): |
str和 unicode 都是 basestring的子类。严格意义上来说,str是字节串,是由unicode经过编码后的字节组成的序列,对utf-8编码的“中”字使用len()函数,得到结果为3,这是因为utf-8编码的“中”为\xe4\xb8\xad。
unicode才是严格意义上的字符串,对字节串str使用正确的字符编码进行解码后获得,并且len(u'中')==1
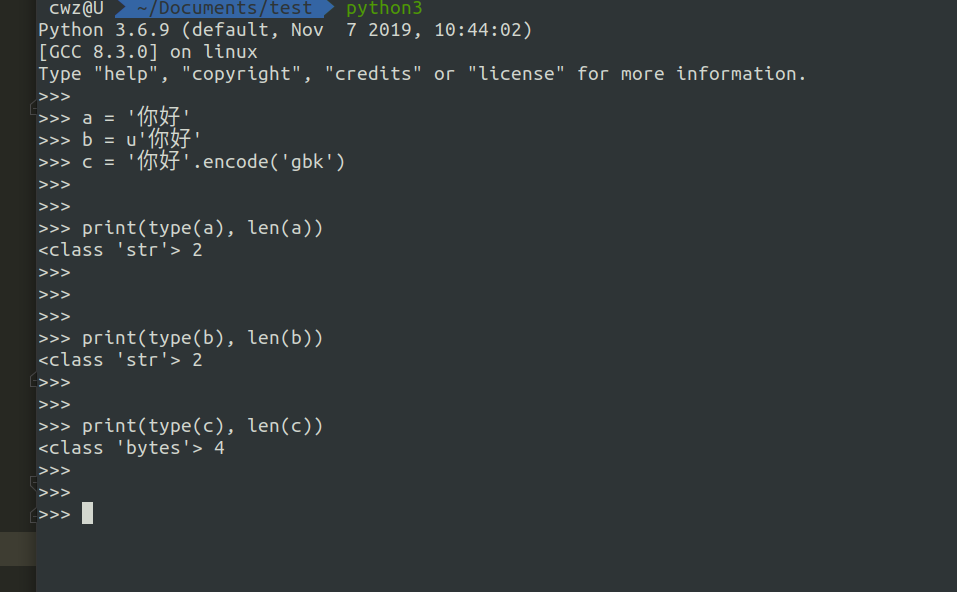
python3字符串类型
python3中对字符串的支持进行了实现类层次的上简化,去掉了unicode类,添加了一个bytes类。从表面上来看,可认为python3中的str和unicode合二为一了。
1 | class bytes(object): |
与python2不同,python3中的str已经是真正的字符串,而字节是用单独的bytes类来表示。也就是说python3默认的就是字符串,实现了对Unicode的内置支持,减轻了程序员对字符串处理的负担。
两者比较总结
对于单个字符的编码,python提供了ord()函数把字符转化为整数,chr()函数把整数转化为相应的字符
1 | print(ord('中')) # 20013 |
- python2默认用ascii 读取字符,python3默认用utf-8读取字符,可以用coding头部指定读取编码的格式
- 字节串(Python2的str默认是字节串)—>decode(‘原来的字符编码’)—>Unicode字符串—>encode(‘新的字符编码’)—>字节串
1 | #!/usr/bin/env python2 |
- 字符串(str就是Unicode字符串)—>encode(‘新的字符编码’)—>字节串
1 | #!/usr/bin/env python3 |
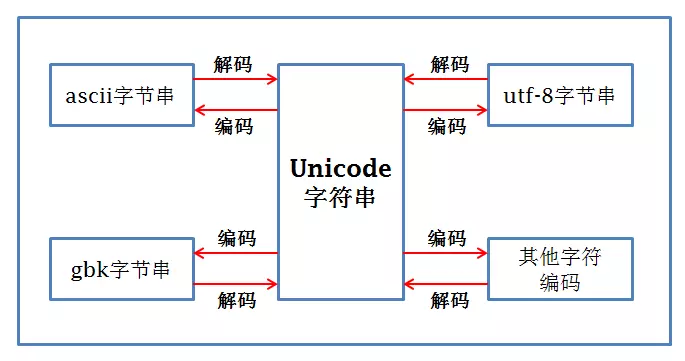
总之:用什么编码存,就用什么编码取。
文件操作
文件的基本操作
什么是文件
文件是操作系统虚拟出来的概念,用来存储信息
操作文件的流程
- 打开文件
- 修改/读取文件
- 保存文件
- 关闭文件
1 | f = open('test.txt', 'w', encoding='utf8') # 打开文件 |
文件打开模式的三种方式
文件操作的基础模式有三种:
- r 只读不可写
- w 清空文件只写不可读
- a 模式 追加 只写不可读
文件操作的两种方法: (默认是t模式)
- t模式为text 文本
- b模式 为 二进制数
t / b模式不能单独使用,需要与r / w / a 连用
文件操作之r模式
1 | f = open('test.txt', 'r', encoding='utf-8') |
f.read()读取文件指针会走到文件末尾,再次读取会 空格
1 | f = open('test.txt', 'r', encoding='utf-8') |
f.read() 一次性读取文件内容,如果文件过大,内存可能会爆炸,可以用f.readline() / f.readlines()读取
1 | f = open('test.txt', 'r', encoding='utf-8') |
rb模式 读二进制文件,不需要字符编码
1 | f = open('test.txt', 'rb') |
文件操作之w模式
w模式,只可写不可读,如果文件存在则清空文件内容写入;如果文件不存在则创建文件写入内容。
1 | f = open('test.txt', 'w', encoding='utf-8') |
文件操作之a模式
a模式,只可写不可读,文件存在则在文件的末端追加内容; 文件不存在则创建文件写入内容。
1 | f = open('test.txt', 'a', encoding='utf-8') |
绝对路径和相对路径
- 绝对路径: 从盘符开始 D:\project\test.py
- 相对路径:执行文件(当前运行的文件)的文件夹下的文件名,执行文件和打开文件属于同一文件夹下
with管理上下文
with提供一个自动关闭文件(解除了操作系统的占用)
1 | with open('test.txt', 'r', encoding='utf-8') as fr: |
文本文件处理的高级应用
三种可读可写的模式
- r+ 可读,可写
- w+ 清空文件可写,可读
- a+ 追加写,可读
文件内指针移动
seek(offset, whence):
offset表示指针的偏移量,
whence 规定只有 0 ,1 ,2 三种模式
- 0表示光标在文件头
- 1表示光标在当前位置
- 2表示光标在文件尾部
1 | with open('36r.txt', 'rb') as fr: |
tell 告诉你当前位置
1 | with open('test.py', 'rb') as fr: |
truncate: 截断
光标从文件头开始,到括号内的数字,之后的都删除
1 | with open('1.txt', 'ab') as fa: |
以上seek,tell,truncate都是以字节为单位的
read 移动光标以字符为单位
1 | with open('1.txt', 'r', encoding='utf8') as fr: |
文件的修改
把硬盘中的文件全部读入内存中,一次性修改,修改完毕在覆盖在硬盘中
1 | import os |
如果文件过大,一次性读入内存会炸掉,可以一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖原文件
1 | import os |




