容器基础——Linux的Namespace和CGroup
这段时间继续学习kubernetes,了解Kubernetes的pod和容器的区别,期间不断深入挖掘,发现需要了解Linux的Namespace、CGroup以及容器运行时等知识。以下内容就当复习一下Linux Namespace和CGroup了。
前言
目前我们提到的虚拟化技术、容器技术都能做到资源层面上的隔离和限制。
而我们关心的容器技术,它实现资源层面上的隔离和限制,依赖于Linux的Namespace和CGroup技术,这是容器技术的基石。下面就重点介绍一下。
Linux的Namespace
linux Namespace提供了一种内核级别隔离系统资源的方法,通过将系统的全局资源放在不同的Namespace中,来实现资源隔离的目的。不同Namespace的程序,拥有独立系统资源。
常见的隔离有
Mount:隔离文件系统挂载点
UTS:隔离主机名和域名信息
IPC:隔离进程间通信
PID:隔离进程的ID
Network:隔离网络资源
User:隔离用户和用户组的ID
当然后面内核更新,又增加了一些Namespace的种类
| Namespace类型 | 隔离资源 | kernel版本 |
|---|---|---|
| IPC | System V IPC和POSIX消息队列 | 2.6.19 |
| Network | 网络设备、网络协议栈、网络端口 | 2.6.29 |
| PID | 进程 | 2.6.14 |
| Mount | 挂载点 | 2.4.19 |
| UTS | 主机名和域名 | 2.6.19 |
| USR | 用户和用户组 | 3.8 |
查看Linux下的Namespace
1 | cd /proc/$$/ns |

Network Namespace 网络命名空间
介绍 一下 ip netns 命令
用来管理网络命名空间 实现网络隔离
每个网络命名空间都提供了一个完全独立的网络协议栈,包括网络接口设备、IPV4和IPV6协议栈、路由表、sockets等
基本命令
1 | ip netns list # 列出网络命名空间 /var/run/netns |

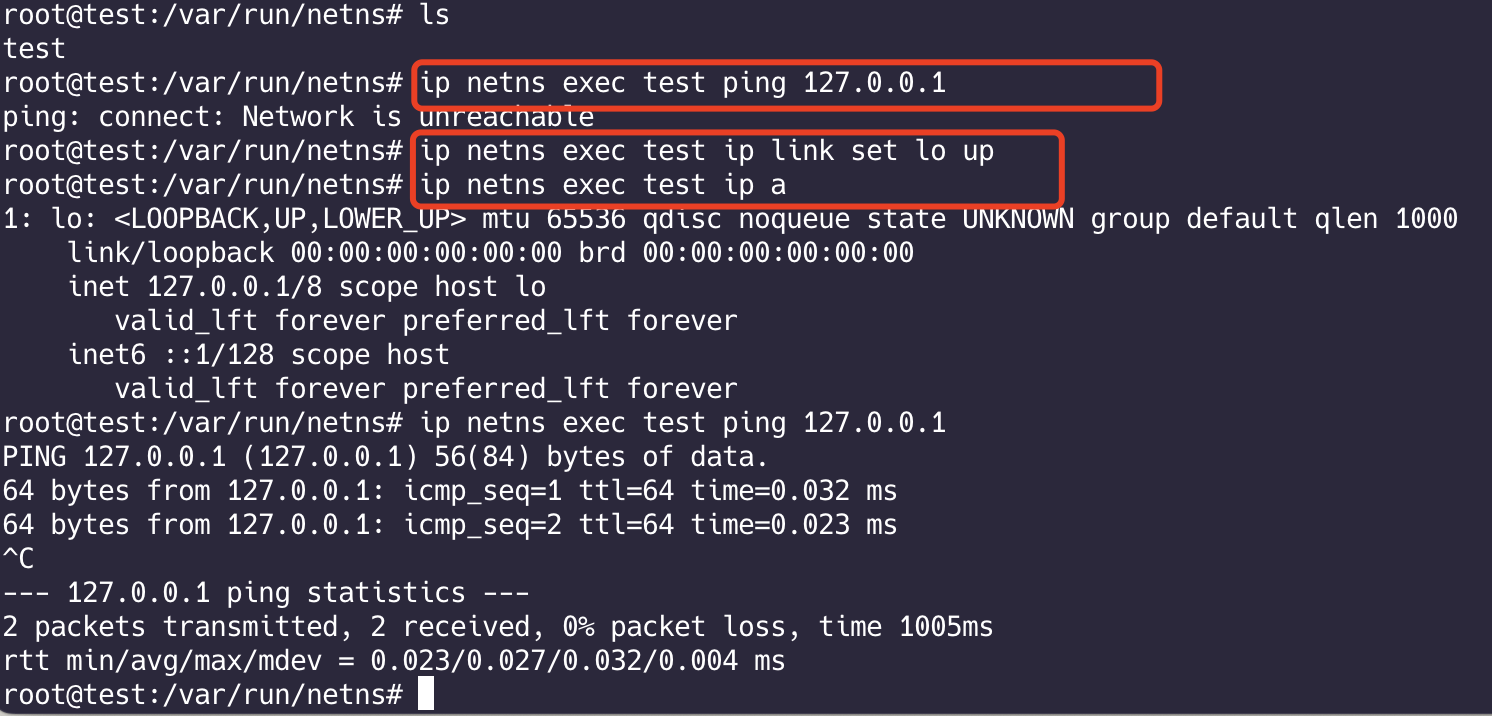
Namespace网络隔离
准备实际操作一番。
使用命令行 创建两个网络命名空间,通过veth对连接在一起,使得两个网络命名空间互通
veth对
解释:VETH(Virtual Ethernet)设备是Linux内核中的一种虚拟网络设备,通常以成对的方式出现。VETH设备通过一个虚拟的以太网链路连接起来,可以用于各种网络相关的任务,如网络命名空间隔离、容器网络等。通过VETH设备,可以在不同的网络命名空间之间建立通信。
主要特点:
- 成对出现
- 一端数据会发送给另一端
预计的效果

这样两者可以相互ping通
操作步骤
1 | # 1、在宿主机上创建veth对 |

这只是基本联通了,数据也没有,没什么用的。。。
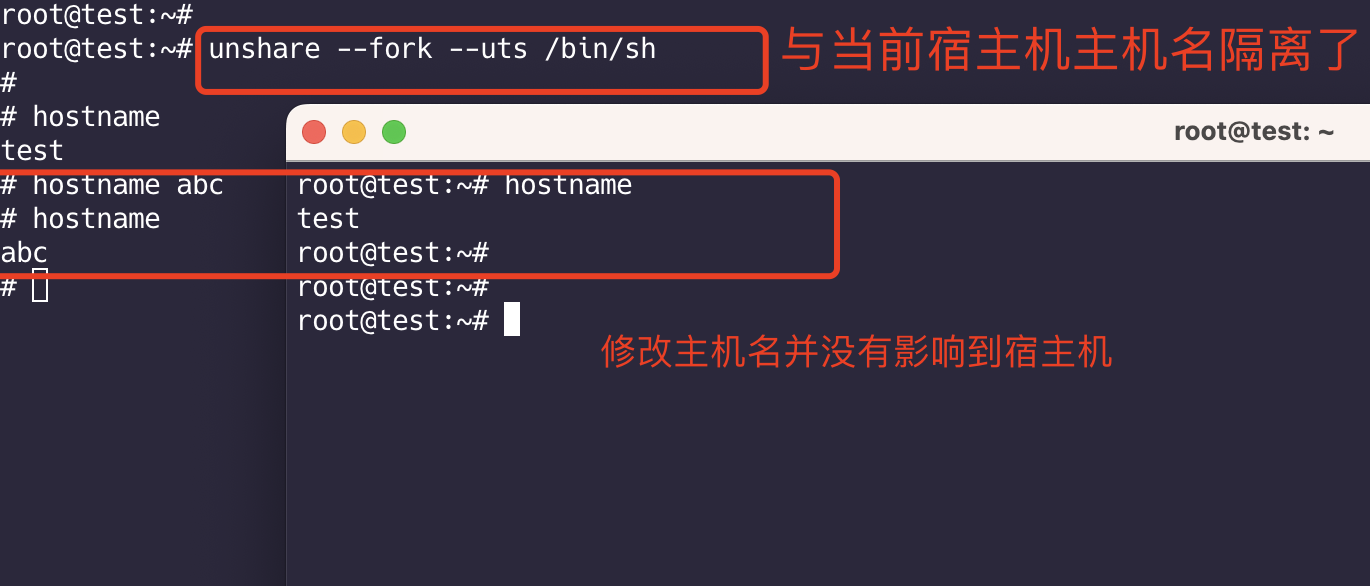
UTS Namespace 主机名隔离
这里使用unshare 命令演示,unshare是Linux 集成工具,使用它可以创建不同的namespace
1 | unshare --fork --uts /bin/sh |
Mount Namespace 隔离文件挂载
挂载的进程可以查看 /proc/[pid]/mounts、/proc/[pid]/mountinfo、/proc/[pid]/mountstats等
1 | # 创建文件夹 |
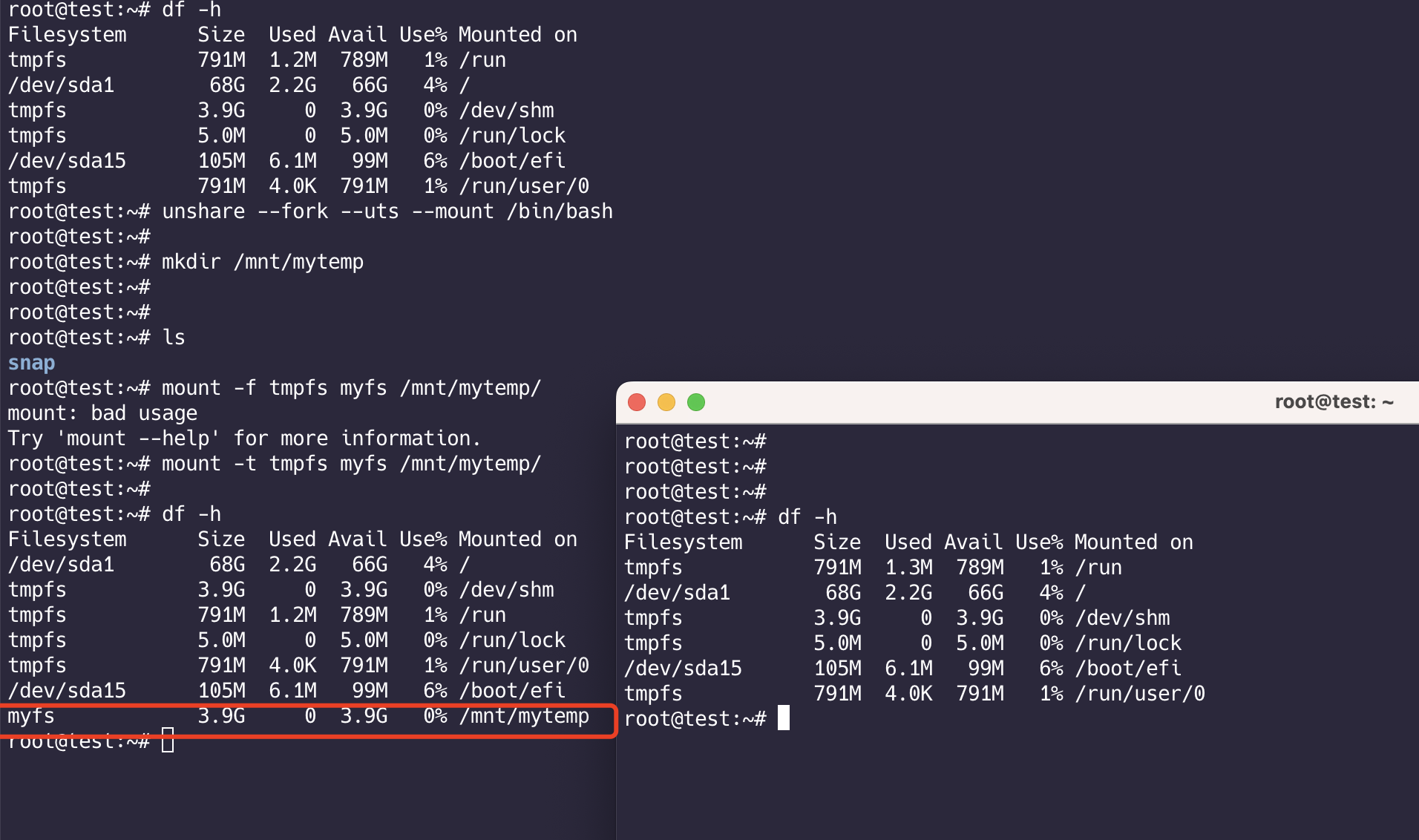
执行ls -l /proc/self/ns

由于开了主机名隔离和挂载隔离,这两个 namespace的id 不一致
USR Namespace 用户隔离
使用的是centos7.9系统
- 用户隔离,用来隔离user权限
- 使用unshare命令在linux上创建不同的namespace
我们使用alpine来模拟
1 | #首先要切换到非root用户 |
开始用户隔离
1 | unshare --fork --user /home/cwz/alpine/bin/busybox sh |
注意:
- 如果要创建出用户空间,
/proc/sys/user/max_user_namespaces这个值需要更改,默认是0 echo 65535 > /proc/sys/user/max_user_namespaces需要切换成root

此时切换回普通用户,执行 用户隔离命令

默认情况下会映射 /proc/sys/kernel/overflowuid

而我们使用docker 进入到容器内部查看 用户id,发现是0
其实我们宿主机普通用户1000 映射到容器中id(对应0),而没有任何设置的情况下,这个容器的root其实就是宿主机的1000,并不是一个真正的root用户。 但是容器内显示的uid是0,其实是被我们进行用户隔离了且映射了,所以就造成了我们看到uid是0的情况。

接下来我们在alpine上操作,也要显示uid是0的效果
我们需要做一些权限处理
为busybox设置capability
- Linux内核 2.2 之后引入了capabilities机制,来对root权限进行更加细颗粒度的划分。如果进程不是特权进程,而且也没有root的有效id,系统就会去检查进程的capabilities,来确认该进程是否有执行特权操作的权限
给我们执行的进程设置特权
1 | sudo setcap cap_setgid,cap_setuid+ep /home/cwz/alpine/bin/busybox |

在busybox下执行
- echo $$ 查看当前进程id(此时我们还没做进程隔离,所以显示的是宿主机上的进程id) 下图id是 16263
- 映射用户的方法是,添加映射信息到
/proc/16263/uid_map和/proc/16263/gid_map中 - 一共三个数字,譬如: 0、1000、256
- 0 就是进程起始id
- 第二个数字是父namespace(可以嵌套)
- 第二、三个数字代表:父namespace中的 1000~1256 映射到 新namespace 的0~256

继续操作,进行映射
1 | echo '0 1000 256' > /proc/16263/uid_map |

参考文档:
https://man7.org/linux/man-pages/man7/user_namespaces.7.html
使用go代码实现隔离Namespace
实现主机名隔离
目录结构:
1 | ├── cmds |
exec.go:
1 | package cmds |
run.go:
1 | package cmds |
执行入口main.go:
1 | package main |
在 Linux终端执行 go run main.go run 发现没有实现主机名隔离,需要修改一下
先熟悉一下几个宏定义:
- IPC CLONE_NEWIPC 进程通信相关
- Network CLONE_NEWNET 网络
- Mount CLONE_NEWNS 挂载
- PID CLONE_NEWPID 进程
- User CLONE_NEWUSER 用户
- UTS CLONE_NEWUTS 主机名
相应的结果内核API定义:
- clone:创建新进程,并放入新的namespace中
- setns:当前进程加入已有的namespace中
- unshare:移除进程(从现有的namespace中)
在run.go文件中修改:
1 | var runCommand = &cobra.Command{ |
重新准备环境
之前下载的alpine可能有些兼容性问题,所以这次使用docker 克隆一个镜像文件出来
1 | docker pull alpine:3.12 |
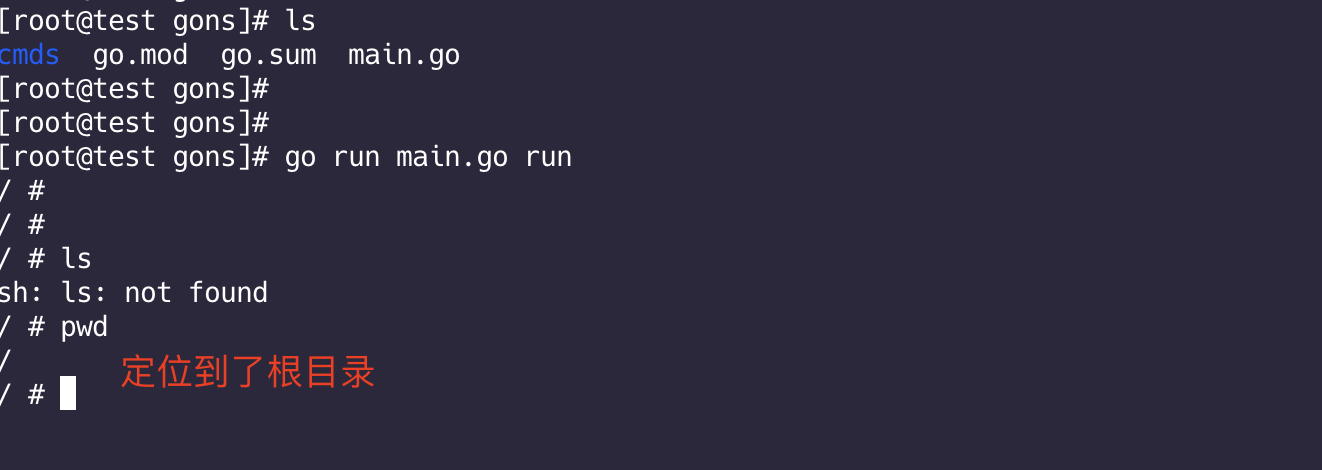
当我们使用docker exec 进入容器 显示的是根目录,而之前我们使用代码测试的是当前目录,显然不合理,所以我们需要修改代码,使得也进入根目录。

只需要修改两点:
- syscall.Chroot 可以用来在指定根目录下运行(chroot)
- os.Chdir 可以来替换当前的工作目录
修改exec.go文件:
1 | var execCommand = &cobra.Command{ |
用户隔离
run.go
1 | package cmds |
注意:
- 如果执行用户隔离程序时出现错误:
fork/exec /proc/self/exe: invalid argument,需要修改/proc/sys/user/max_user_namespaces的默认值
进程隔离
测试:
1 | unshare --fork /root/alpine/bin/busybox sh |
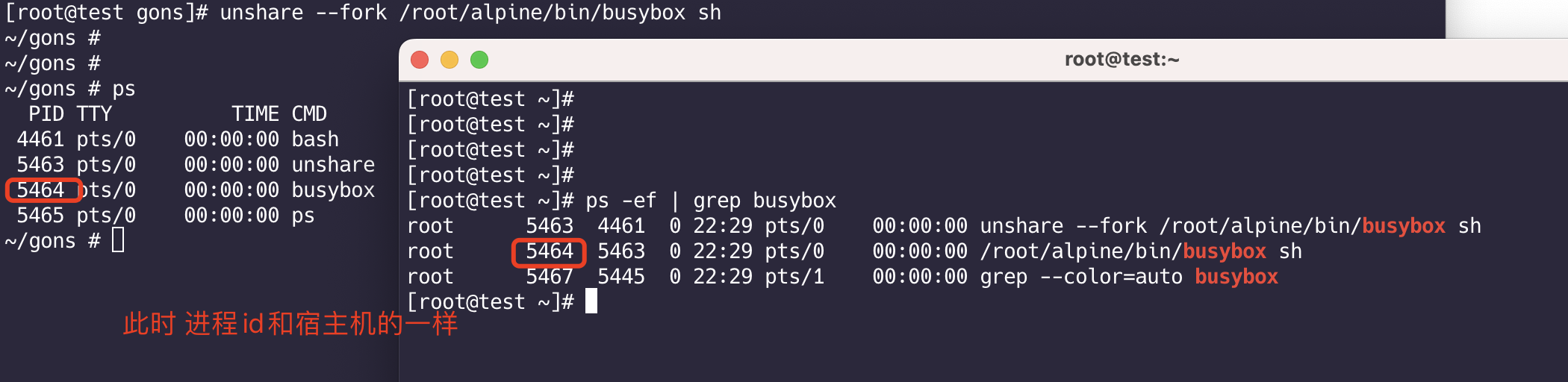
1 | # 进行隔离 |
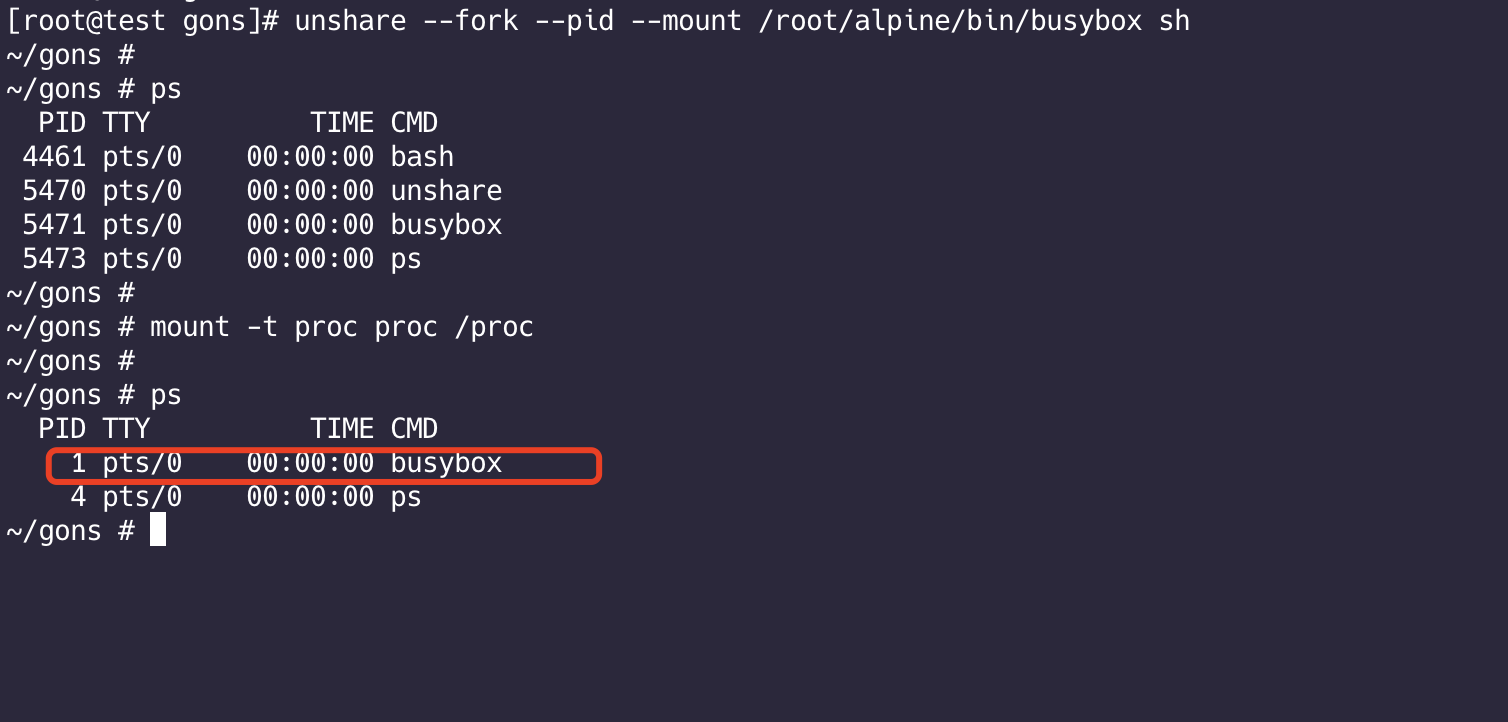
此时就实现了进程隔离,busybox进程id为1
代码实现:
run.go:
1 | package cmds |
exec.go:
1 | package cmds |

Linux的CGroups
CGroups (Control Groups) 是Linux下用于对一个或一组进程进行资源控制和监控的机制。利用CGroups可以对诸如CPU使用时间、内存、磁盘I/O等进程所需资源进行限制。kubernetes允许用户为pod的容器申请资源,当容器在计算节点上运行起来时,可以通过CGroups来完成资源的分配和限制。
CGroups为每种可以控制的资源定义了一个子系统。
文档:https://man7.org/linux/man-pages/man7/cgroups.7.html
任务(task):理解为进程
控制组(cgroup):用来设定资源的配额。任务(进程)可以加入到某个组,也可以迁移。可以包含多个子系统
层级(hierarchy):控制组有层级关系,类似树的结构,子节点的控制组继承父控制组的属性(资源配额、限制等)
子系统(subsystem):也叫资源控制器,比如memory子系统可以控制进程内的使用。子系统需要加入到某个层级,然后该层级的所有控制组,均受到这个子系统的控制
cpu:限制进程的使用率
cpuacct:统计cgroups中的进程的cpu的实验报告
cpuset:为cgroups中的进程分配单独的cpu节点或者内存节点
memory:限制进程的memory使用量
blkio:限制进程的块设备io
devices:控制进程能够访问某些设备
net_cls:标记cgroups中进程的网络数据包,然后可以使用tc模块(traffic control)对数据包进行控制
net_prio:限制进程网络流量的优先级
huge_tlb:限制hugeTLB的使用
freezer :挂起或者恢复cgroups中的进程
ns:控制cgrouops中的进程使用不同的namespace

还是直接演练一番来的实在
1 | yum install -y libcgroup-tools.x86_64 |
cgroups以文件挂载的方式存在,其中 /sys/fs/cgroup 这个文件夹 是挂载到tmpfs(临时内存文件夹)的
限制CPU使用率
进入/sys/fs/cgroup/cpu,创建一个文件夹myapp,进入myapp,发现会自动生成对应的配置文件

首先先解释一下这几个文件是干啥的
- cpu.shares 是在该cgroup能获得CPU使用时间的相对值,最小值为2。如果两个cgroup的cpu.shares都为100,那么他们可以得到相同的CPU时间。如果另外一个cgroup的cpu.shares是200,那么他可以得到两倍于cpu.shares=100的cgroup获取的CPU时间。但是如果一个cgroup中的任务处在空闲状态,不使用任何的CPU时间,则该CPU时间就可以被其他的cgroup所借用。也就是说 cpu.shares 主要表示当系统繁忙时,给该cgroup分配的CPU时间份额。
- cpu.cfs_period_us和cpu.cfs_quota_us cpu.cfs_period_us用于配置时间周期长度,单位为us(微秒)。cpu.cfs_quota_us用来配置当前cgroup在cpu.cfs_period_us 时间内最多使用的CPU时间数,单位为us(微秒)。这两个参数被用来设置该cgroup能使用的CPU的时间上限。如果不想对进程使用的CPU设置限制,可以将cpu.cfs_quota_us 设置为-1。
- cpu.stat cgroup内的进程使用的CPU时间统计
- cpuacct.usage 包含该cgroup及其子cgroup下进程使用CPU的时间,单位是ns(纳秒)
具体操作:
- 随便写个死循环程序,然后编译上传到服务器
1 | package main |

可以看到,如果不限制,直接cpu打满
1 | # cd 进入这个myapp |
CFS 表示 Completely Fair Scheduler 完全公平调度器(Linux内核功能,负责进程调度)
有关文档:https://kernel.org/doc/Documentation/scheduler/sched-bwc.txt
接下来操作:
1 | cgexec -g cpu:myapp ./myapp |

还可以 把 当前运行程序的进程id放入 cgroup.procs 中来限制

限制内存使用
1 | cd /sys/fs/cgroup/memory |
随便写一个程序:
1 | package main |
上面的程序 不断创建协程,协程 使用 select {} 卡住,协程不能退出,无法释放后内存,内存最终会用爆掉。
这是个内存泄漏的程序
需要修改两个文件:
memory.limit_in_bytes 设定用户的内存(包括文件缓存)的最大用量。默认单位是字节。可加后缀代表更大的单位—— k
、m、g等
memory.swappiness 设置如何使用swap分区。swappiness=0 时 表示最大限度使用物理内存,然后才是swap空间
- 假设swappiness=30,表示当内存使用到70%,就会开始swap交换
1 | echo 1g > memory.limit_in_bytes |
看效果:


当内存超过一定限制,这个程序就自动杀死了




