01-命令行基础
使用习惯
- 类Unix系统通用的使用习惯
- shell
- 用于运行系统指令的程序
- shell中运行的多条系统指令可形成shell脚本
- Bourne Shell(贝尔实验室)
- Bourne-again:Bash(ubuntu默认采用)
- 通常称为终端
- 命令提示符
- name@host:path$
- name@host:path#
基本shell命令
- 基本命令
- cat /etc/passwd(合并显示多个文件内容)
- 输入输出
- 进程通过输入输出流读写数据
- 默认输入输出称为 stdin / stdout
- cat命令的默认I/O就是终端
- 第三个标准流stderr
- Ctrl-D结束当前输入
- Ctrl-C无论当前情况强制结束
ls-列出目录内容
- ls -l 详细内容(权限、inode占用数量、属主、属组、大小、修改时间或创建时间、文件或文件夹名字)
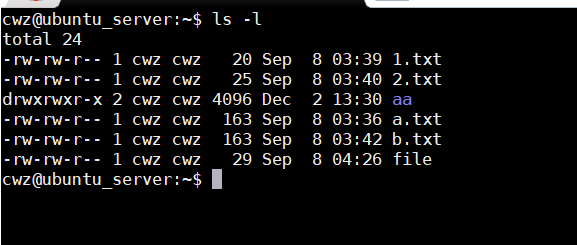
inode:对一个硬盘分区,可以把划分出来的分区进一步 的分成一个个的存储单元的小块,每一个小块对应着一个个的inode编号。比如说有100M的分区,1M作为一个数据块,把数据块进行编号。第一个数据块就是1号,第100块就是100号。也就是说,这一个分区最多能存多少文件,由inode来决定的。操作系统来使用硬盘存储空间的时候,一次性存储一个文件就要占用一个inode号,不是按照字节来计算的,是按照每一个inode号对应的存储空间的块来使用存储空间的。比如说,一个inode对映数据块是1M的话,那么100M的存储空间只能有100个inode号,这样哪怕你只存一个字节的文件在硬盘上,也会占用1M的空间。这样会导致,哪怕你的存储物理空间没有被耗尽,但是你的inode号被耗尽了,也会导致你的物理硬盘不能再存储新的文件。
ls -a 包括隐藏的所有内容

ls -d 只显示目录自身信息,显示所在目录本身的信息
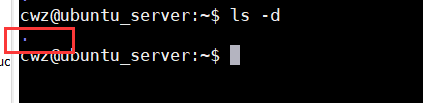
结合使用:ls -dl

显示 点 目录本身的信息
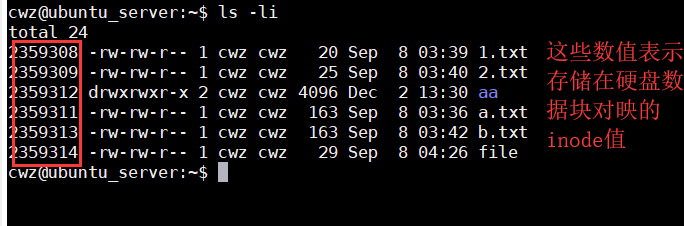
ls -i 显示inode信息
ls -S 按文件从大到小排序, ls -Sr按文件从小到大排序
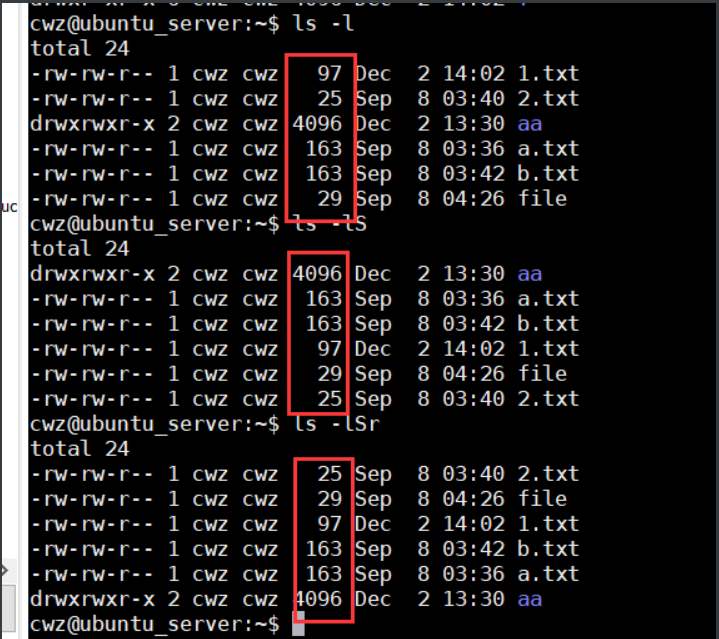
ls -r 倒叙排列
ls -t 按修改时间排序
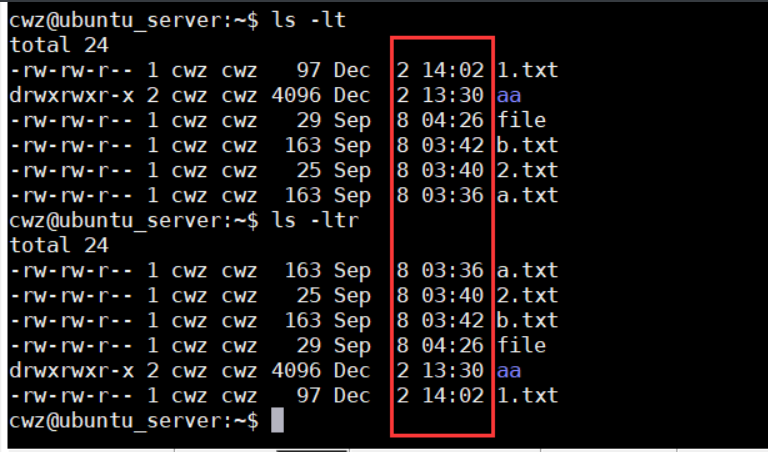
ls -h 文件大小以便于人类阅读的方式显示
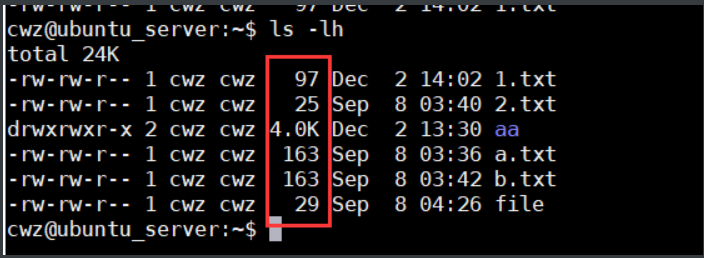
l l == ls -la 显示所有文件详情,包括隐藏文件信息
在其他发行版本可能没有这个命令
cp -拷贝
- cp file1 file2
- cp file1 dir/file2
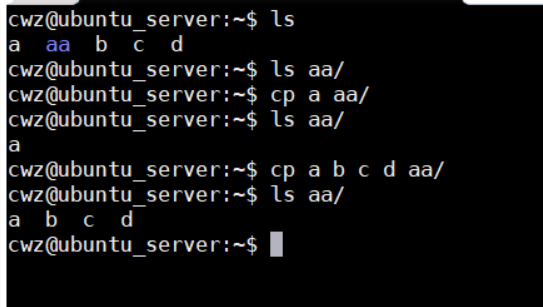
- cp -R/r 拷贝目录及其中全部内容
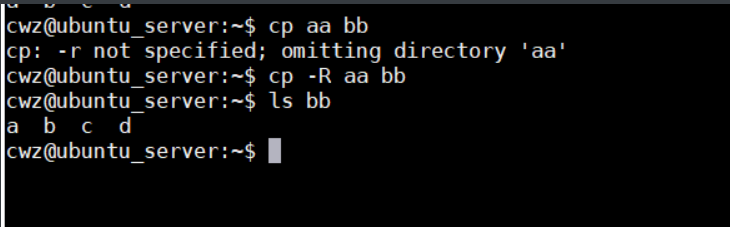
- cp -l 硬链接拷贝(ls -li) 如 :cp -l a a2 这样拷贝inode值是一样的
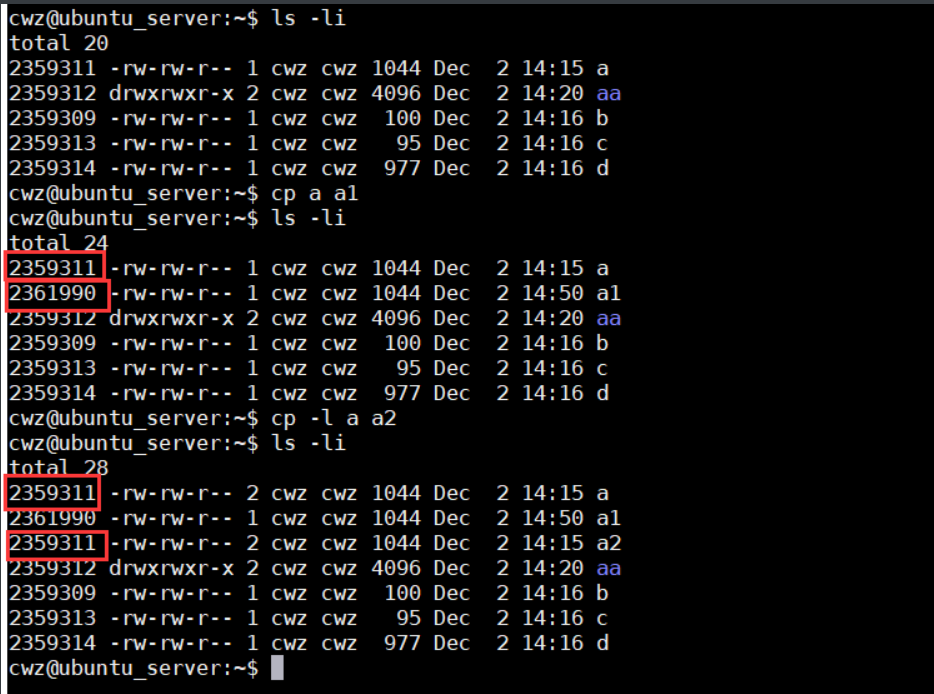
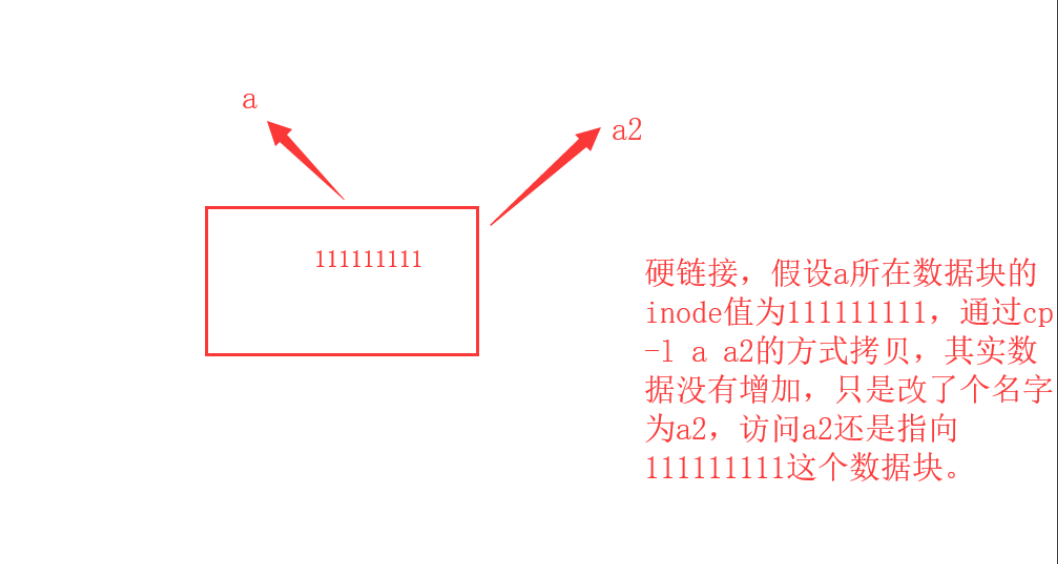
硬链接也就是 同一个数据起了两个名字
- cp -s 软链接拷贝 相当于快捷方式
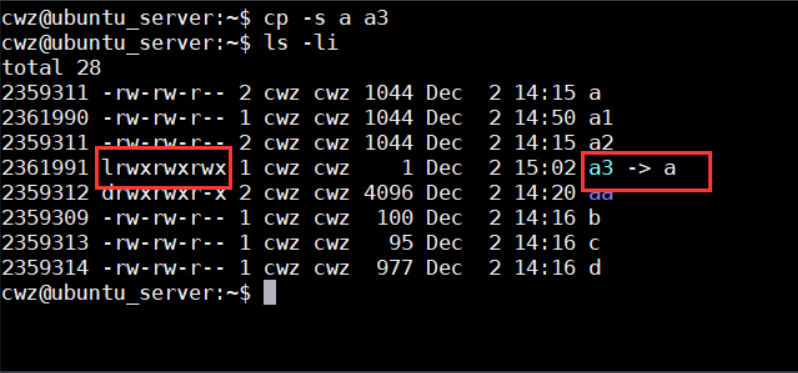
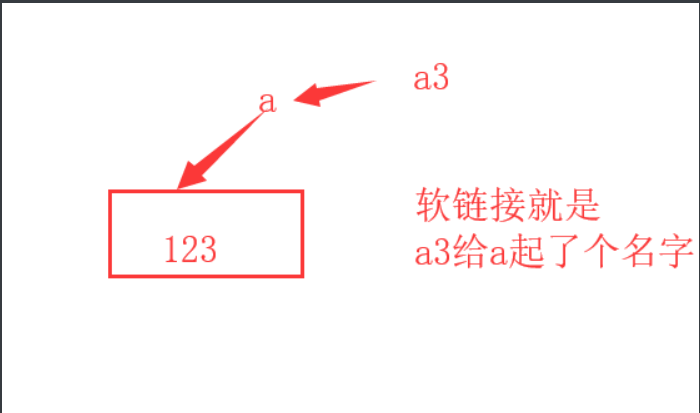
如果a删除了, a3就不能访问到a
cp -u 源比目标新时才拷贝
- 复制文件,只有源文件file1较目的文件file2的修改时间新时,才复制文件
cp -u file1 file2
- 复制文件,只有源文件file1较目的文件file2的修改时间新时,才复制文件
| -f | 若目标文件已存在,则会直接覆盖原文件 |
|---|---|
| -i | 若目标文件已存在,则会询问是否覆盖 |
| -p | 保留源文件或目录的所有属性 |
| -r | 递归复制文件和目录 |
| -d | 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录 |
| -l | 对源文件建立硬连接,而非复制文件 |
| -s | 对源文件建立符号连接,而非复制文件 |
| -b | 覆盖已存在的文件目标前将目标文件备份 |
| -v | 详细显示cp命令执行的操作过程 |
| -a | 等价于“dpr”选项 |
mv-移动
- mv file1 file2 相当于重命名
- mv file1 file2 dir/ 移动文件到目录
- mv -f 强制移动、覆盖目标
touch-创建空文件
- 若文件名存在,修改文件mtime,但不修改内容
- touch file
rm-删除
- rm filename 删除文件
- rm -rf dir/ 递归删除
- rm -i 每删除前提醒
- rm -d 删除空目录
echo- 将命令行参数显示在stdout
echo hello world!
1
2
3
4
5chengwz@Ubuntu:~$ echo "hello world!"
hello world!
chengwz@Ubuntu:~$ echo \"hello world\!\"
"hello world!"
echo -n 显示结束不换行
1
2chengwz@Ubuntu:~$ echo -n a
achengwz@Ubuntu:~$
echo -e 解释反斜线转义符
1
2
3
4
5
6
7
8
9
10
11chengwz@Ubuntu:~$ echo a
a
chengwz@Ubuntu:~$ echo a\n
an
chengwz@Ubuntu:~$ echo -e a\n
an
chengwz@Ubuntu:~$ echo -e a\\n
a
这里换行
chengwz@Ubuntu:~$ echo -ne 123\\b
12chengwz@Ubuntu:~$echo $HOME
1
2
3
4
5
6chengwz@Ubuntu:~$ echo $HOME
/home/chengwz
chengwz@Ubuntu:~$ echo $SHELL
/bin/bash
chengwz@Ubuntu:~$ echo $USER
chengwz
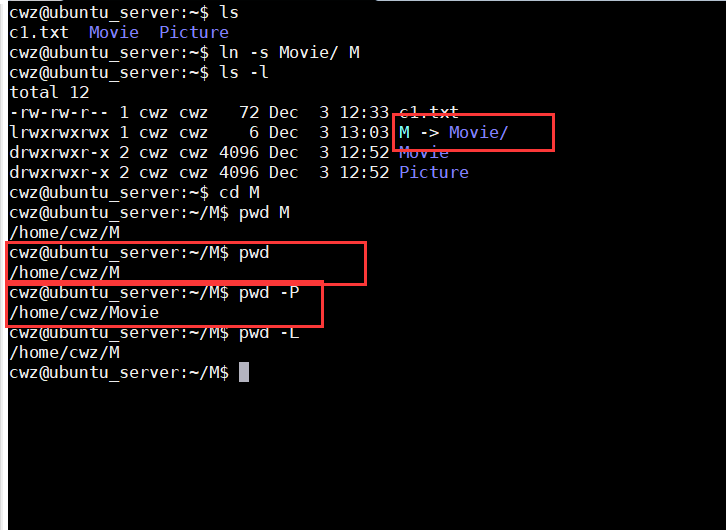
pwd
查看当前完整目录
- 适用于提示符不显示完整路径
pwd -P物理路径(软连接对应的正式路径)pwd -L逻辑路径(软连接自身路径)
mkdir
mkdir dir 创建目录
mkdir -p a/b/c/d 按需创建多层目录
rmdir
只能删除空目录
rmdir -p a/b/c
grep
grep是“global search regular expression and print out the line”的简称,意思是全面搜索正则表达式,并将其打印出来。这个命令可以结合正则表达式使用,它也是linux使用最为广泛的命令。
linux系统支持三种形式的grep命令,大儿子就是grep,标准,模仿的代表。二儿子兴趣爱好多-egrep,简称扩展grep命令,其实和grep -E等价,支持基本和扩展的正则表达式。小儿子跑的最快-fgrep,简称快速grep命令,其实和grep -F等价,不支持正则表达式,按照字符串表面意思进行匹配。
常用参数:
| -i | 搜索时,忽略大小写 |
|---|---|
| -c | 只输出匹配行的数量 |
| -l | 只列出符合匹配的文件名,不列出具体的匹配行 |
| -n | 列出所有的匹配行,显示行号 |
| -h | 查询多文件时不显示文件名 |
| -s | 不显示不存在、没有匹配文本的错误信息 |
| -v | 显示不包含匹配文本的所有行 |
| -w | 匹配整词 |
| -x | 匹配整行 |
| -r | 递归搜索 |
| -q | 禁止输出任何结果,已退出状态表示搜索是否成功 |
| -b | 打印匹配行距文件头部的偏移量,以字节为单位 |
| -o | 与-b结合使用,打印匹配的词据文件头部的偏移量,以字节为单位 |
less
每次一页显示输出内容, 是more的增强版
less file
快捷键:
- z/b 向前/后翻一页
- v 进入编辑模式
- g/G 直接跳到第一行/最后一行
- /word 向前搜索关键词
- ?word 向后搜索关键词
- n/N 正向/反向继续搜索关键词
- q 退出
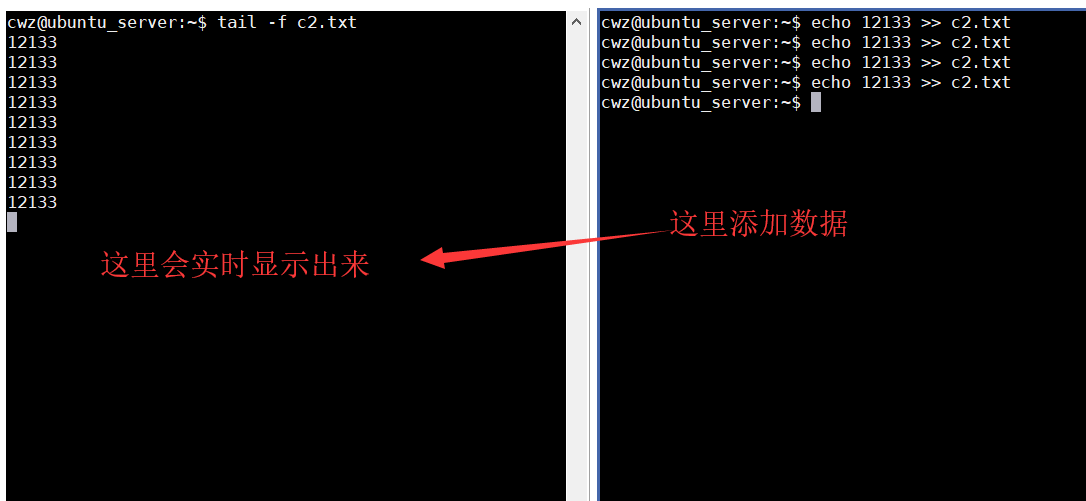
head / tail
- 显示文件头部 / 尾部内容
- 默认显示10行
- 加参数
-nhead c1.txt -n 4或者head -4 c1.txtn后面指定显示的行数 - tail 加
-f参数tail -f c2.txt实时更新数据
diff
比较文本文件
diff file1 file2
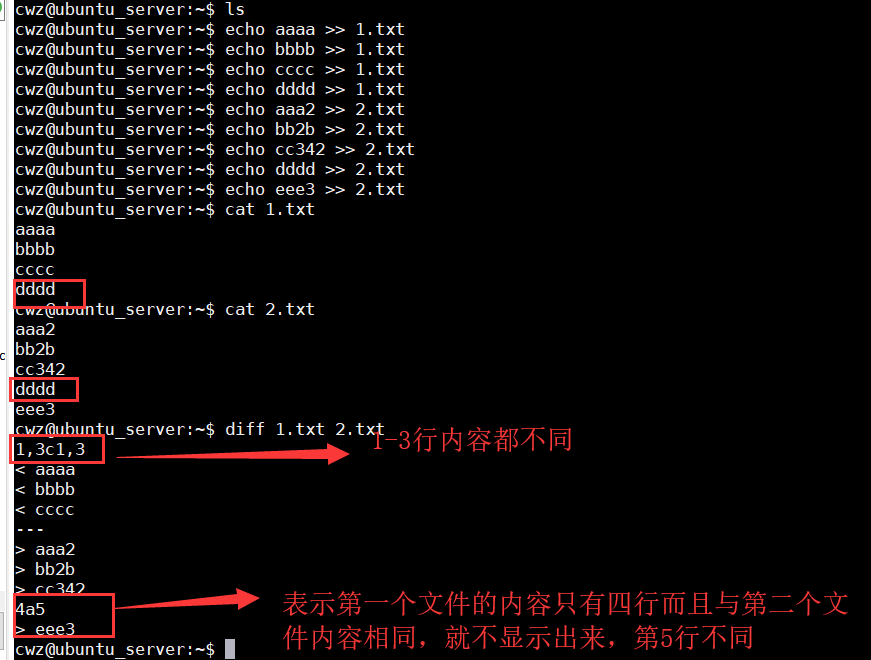
diff -u file1 file2
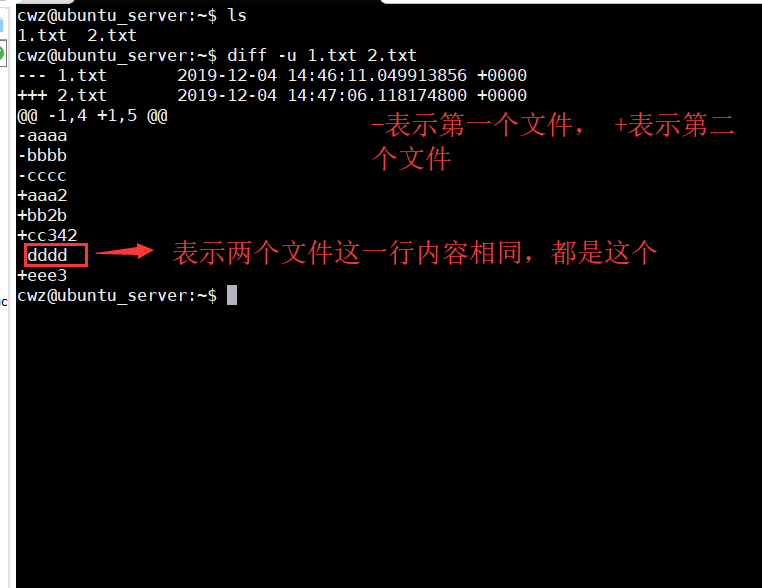
diff -y 1.txt 2.txt 配合-W参数限制宽度
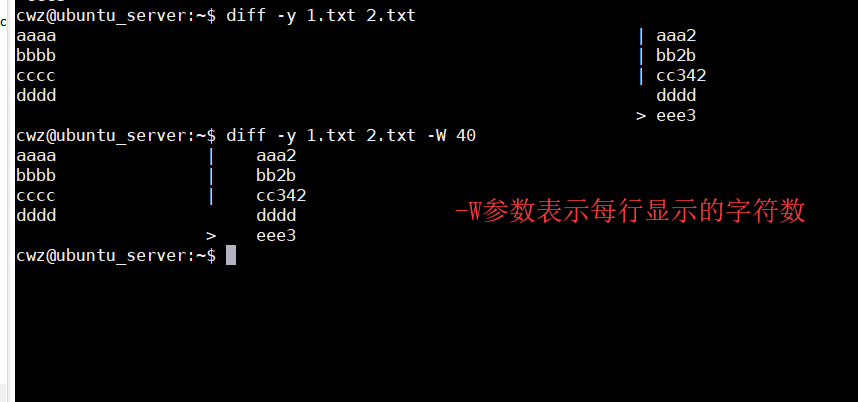
diff -y -i 1.txt 2.txt -i 参数忽略大小写
比较文件夹
diff a/ b/
file命令
检测文件格式
- 空文件或特定数据格式的文件
顺序执行三种测试集
- filesystem: 匹配系统头文件
<sys/stat.h> - magic:匹配文件头部魔术值, 用
file -l参数查看 - language:匹配文件起始的字符类型,如 ASCII、UTF8
- 三种匹配模式都不匹配返回 这是一个data文件
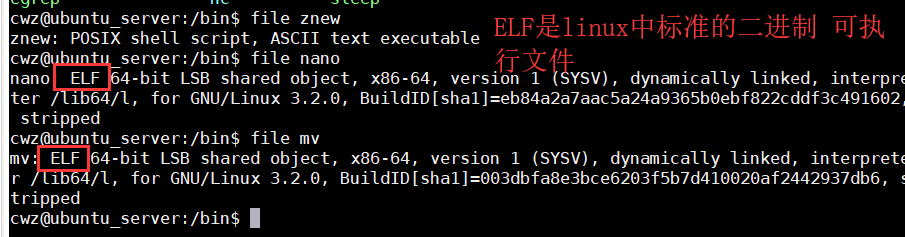
file -f 文件列表 查看多个文件
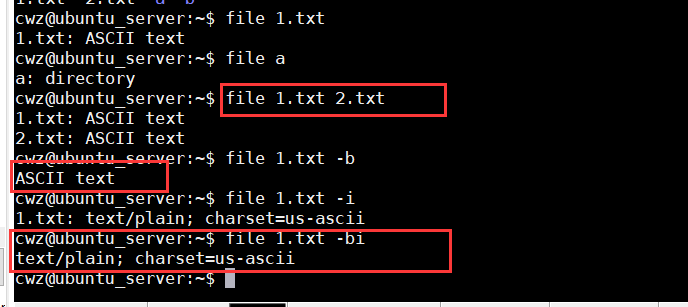
file -b 省略文件名信息
file -i 显示mime类型
find / locate
locate 基于文件索引进行搜索,会定期的在操作系统中把所有的文件名做一个索引,把这个信息保存起来
- 不验证文件是否存在,速度快但结果不准确
- 周期性更新索引, 可以手动更新索引:
sudo updatedb
find 通过文件名查找
sudo find / -name 1.txt 查找1.txt文件,但不知道在哪个文件夹
支持通配符: sudo find / -name a*.txt
find根据文件类型查找:
find -type d 找目录 find -type f 找文件 find -type l 找链接
find时间相关的用法
1 | find / -mtime +1 # 找1分钟之前的文件 |
stat命令
stat命令用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细。
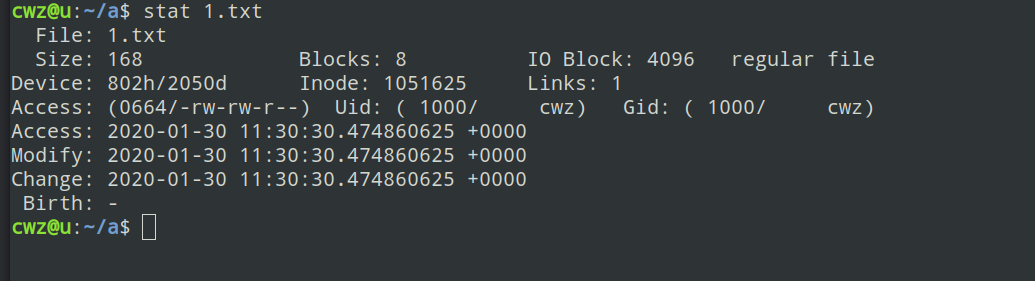
简单的介绍一下stat命令显示出来的文件其他信息:
1 | - File:显示文件名 |
Linux下的三个时间:
- Access Time:简写为atime,表示文件的访问时间。当文件内容被访问时,更新这个时间
- Modify Time:简写为mtime,表示文件内容的修改时间,当文件的数据内容被修改时,更新这个时间。
- Change Time:简写为ctime,表示文件的状态时间,当文件的状态被修改时,更新这个时间,例如文件的链接数,大小,权限,Blocks数。
sort命令
将文件内容进行排序,默认按文件内容的数字字母排序
1 | sort a.txt |
获取帮助
man
Linux系统有完善的文档体系,Manual是最主要的帮助
1 | man ls # 列出ls命令的详细的参数命令 |
每个命令的手册页可以使用数字编号引用片段(section)
1 | man 5 passwd # 按照section查看 |
info
GNU项目不太喜欢man命令,开发了info,用法和man类似
有时优于man,有时不是
其他
1 | /usr/share/doc # 这个目录下会有帮助文档 |
Shell输入与输出
输出重定向
1 | cwz@u:~$ ls a/ |
管道
前面的输出作为后面的输入
1 | ifconfig | grep inet | awk '{print $2}' |
标准输入重定向
1 | head < /proc/cpuinfo |
标准错误
stderr,报错包含重要信息
1 | # 0代表标准输入、1代表标准输出、2代表标准错误 |
常见的保存信息
- No such file or directory(查看不存在的文件目录)
- FIle exists(创建与文件同名的目录)
- Not a directory,is a directory(把文件当目录)
- No space left on device(磁盘空间不足)
- Permission denied(权限不足)
- Operation not permitted(杀掉不属于自己的进程)
- Segmentation fault,Bus error(程序访问禁用内存)s
进程管理
进程就是运行中的程序文件
- PID:进程ID
- TTY:运行进程中的终端设备
- STAT:进程状态(Sleep、Running)
- TIME:该进程占用CPU时间
- COMMAND:命令名称
ps命令
1 | ps -x # 当前用户启动的进程 |
结束进程:
1 | kill pid |
归档打包和压缩
gzip
- Linux标准压缩程序
gzip file,压缩之后源文件不保存 - 解压:
gunzip file.gz - gzip不做多文件或目录的归档打包
tar打包归档(Archive)
1 | tar cvf a.tar file1 file2 # 将file1,file2打包成a.tar |
解包:
1 | tar xvf file.tar |
tar结合gzip使用:
1 | tar zcvf b.tar.gz file1 file2 # 参数z其实是调用了gzip |
查看包的目录结构:
1 | tar -tvf a.tar.gz # 不解压,显示包里面的内容 |
bzip2压缩
压缩文件是 .bz2
比gzip压缩速度慢,文本压缩比会高一点
1 | bzip2 f # 压缩f文件,得到f.bz2 |
sudoer
出于安全的考虑使用 sudo
1 | cat /etc/group | grep sudo |
如果要把组添加到sudo中:
1 | # 编辑visudo |
1 | User_Alias ADMINS = user1,user2 |
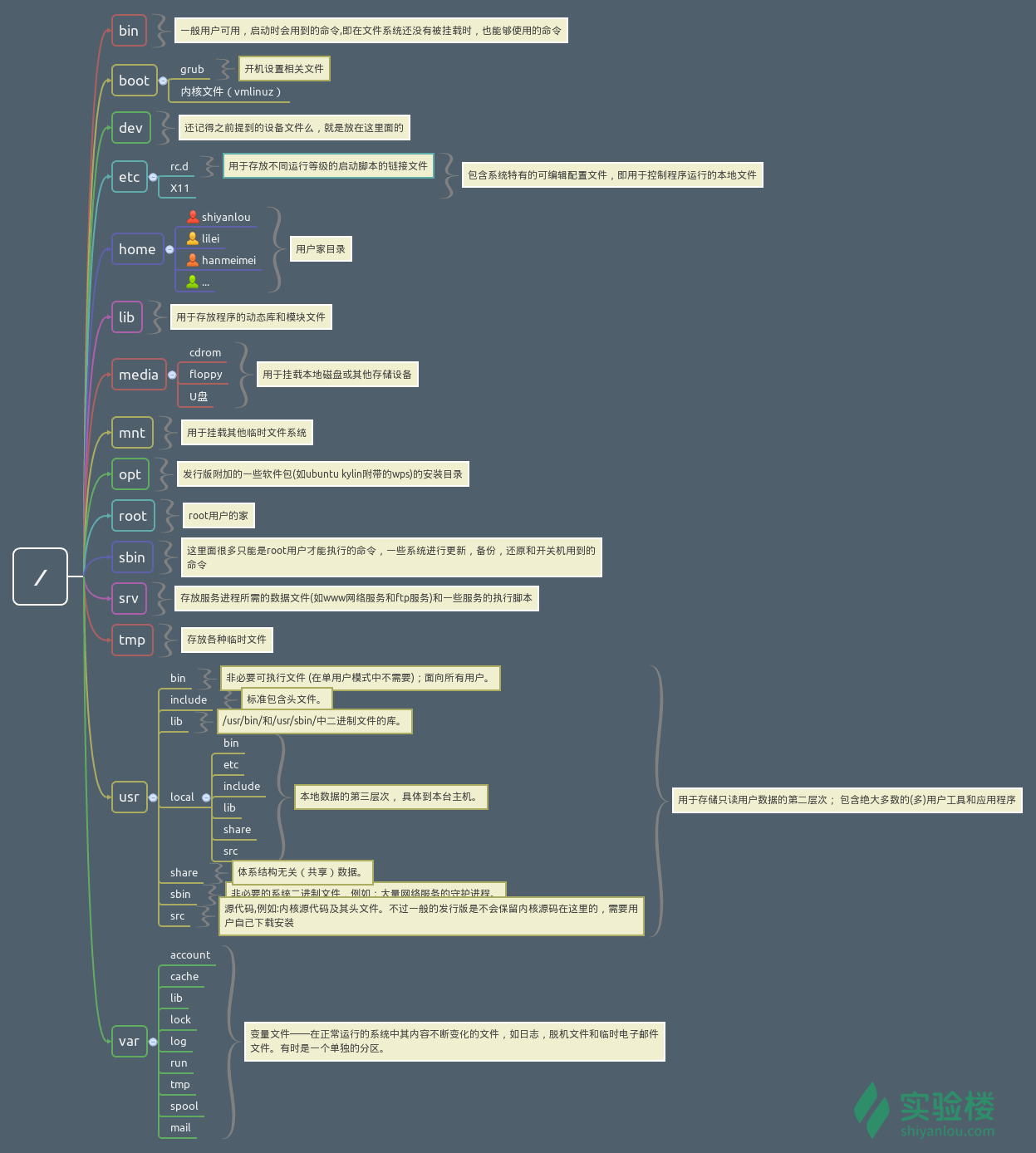
目录结构
FHS(), Filesystem Hierarchy Standard(文件系统层次化标准)的缩写, FHS定义了两层规范,第一层是, / 下面的各个目录应该要放什么文件数据,例如/etc应该要放置设置文件,/bin与/sbin则应该要放置可执行文件等等。
inode和block
什么是inode和block
所谓的inode就是索引节点(index node)的意思,在每一个存储设备被格式化创建文件系统后,所有的文件大致被分为了两部分,分别是inode和block。
其中inode用来存储文件属性信息,其中包括了文件大小,文件的归属者,文件的归属组,权限,类型,修改时间,以及指向文件实体数据(block)的指针。
block中存储的就是文件的实际数据,比如说,照片,视频,音频等等,但是有一点需要注意!就是inode当中不包含文件名。一个文件的文件名,存储在上级目录的block中。
其实inode和block之间的关系就像是一本书一样,inode是一本书的目录,一本书会有很多内容,一个知识点或者一个故事会占很多页,一个block就相当于书中的一页内容。
所以说一般情况下一个inode会对应一个或多个block。

inode的大小
因为inode要存放文件的属性信息,所以inode是有大小的,CentOS5 inode的默认大小为128字节,而CentOS6 inode的默认大小是256字节,inode的大小在文件系统被格式化之后就无法更改了,格式化前可以指定inode大小。
1 | dumpe2fs /dev/vda1 | grep -i 'inode size' # 显示inode大小 |
inode小结
- 磁盘分区格式化ext4文件系统后会生成一定数量的inode与block。
- inode是索引节点,作用是存放文件的属性信息以及作为文件的索引(指向文件的实体)
- inode表现形式为一串数字,不同文件对应的inode在OS中是唯一的
- inode相同的文件,互为硬链接文件(文件又一个入口)
- 一个文件被创建后至少要占用一个inode和一个block。
- inode总量和大小查看:
dumpe2fs /dev/vda1 | grep -Ei 'inode size|inode count' - 如何生成及指定inode大小:
mkfs.ext4 -b 2048 -l 256 /dev/sdb
block的小结
- 磁盘读取数据是按block为单位读取的
- 一个文件可能占用多个block。每读取一个block就会消耗一次磁盘I/O
- 如果要提升磁盘IO性能,那么就要尽可能一次性读取数据尽量的多
- 一个block只能存放一个文件的内容,无论内容有多小。如果block 4K,那么存放1K的文件,剩余3K就浪费了
- block并非越大越好。block太大对于小文件存放就会浪费磁盘空间,例如:1000K的文件,block为4K,占用250个block,block为1K,占1000个block
- 大文件(大于16K)一般设置block大一点,小文件(小于1K)一般设置block小一点
- block太大例如4K,文件都是0.1K的,大量浪费磁盘空间;block太小例如1K,文件都是1000K,消耗磁盘IO
- 文件较大时,block设置大一些会提升磁盘访问效率







